In the field of Machine Learning and Deep Learning it is very essential to learn Algorithm very much.
One such algorithm that i am going to explain is CNN(Convolutional Neural Network)which is one of the famous algorithms used for images recognition, images classifications. Objects detections, recognition faces etc., are some of the areas where CNNs are widely used.
An Image is a matrix of pixel values
Essentially, every image can be represented as a matrix of pixel values.
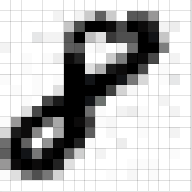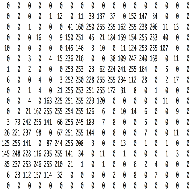

CNN takes an image as an input and does different mathematical operation on the input and gives output as classification types based on the label given as input.
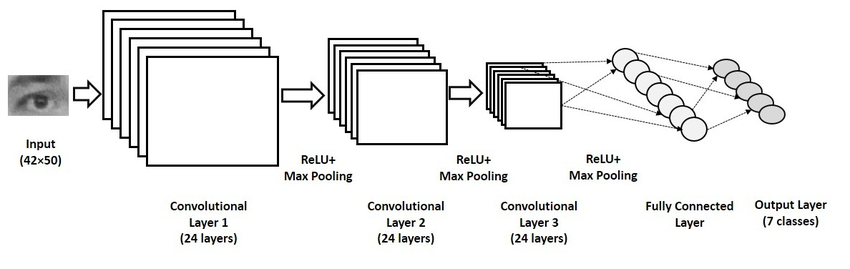
STACK OF CNN ARCHITECTURE
- Input Image
- Convolutional Layer + Activation FUnction
- Pooling Function
- Fully Connected Layer & SOFTMAX FUNCTION
- OUTPUT LAYER
INPUT IMAGE
The algorithm takes image format as input and the resolution of all the input images must be same. So, the model can train on all the images easily.
CONVOLUTIONAL LAYER
Convolution is the first layer to extract features from an input image. Convolution preserves the relationship between pixels by learning image features using small squares of input data. It is a mathematical operation that takes two inputs such as image matrix and a filter or kernal


Computer sees every image as an array of pixels with RGB color value.Then the convolution of 5 x 5 image matrix multiplies with 3 x 3 filter matrix which is called “Feature Map” as output shown in below


Convolution of an image with different filters can perform operations such as edge detection, blur and sharpen by applying filters.
ACTIVATION FUNCTION
Activation function decides, whether a neuron should be activated or not by calculating weighted sum and further adding bias with it. The purpose of the activation function is to introduce non-linearity into the output of a neuron.


There are many Activation Function available ,the most popular one is RELU
RELU stands for Rectified Linear unit. The output is ƒ(x) = max(0,x).


POOLING LAYER
The pooling layer, is used to reduce the spatial dimensions, but not depth, on a convolution neural network, model.specially when they want to “learn” some object specific position .
TYPES
- MAX POOLING
- AVERAGE POOLING
- SUM POOLING
MAX POOLING helps to find the maximum element in the matrix (i.e a 2x2 matrix which has maximum element is given as a output)
FULLY CONNECTED NETWORK
The layer we call as FC layer, we flattened our matrix into vector and feed it into a fully connected layer like neural network.


In the above diagram, feature map matrix will be converted as vector (x1, x2, x3, …). With the fully connected layers, we combined these features together to create a model. Finally, we have an activation function such as softmax or sigmoid to classify the outputs as cat, dog, car, truck etc.,
REFERENCE
- http://cs231n.github.io/convolutional-networks/
- Video reference to understand the CNN https://www.youtube.com/watch?v=YRhxdVk_sIs&t=2s
Follow me personally on
Linked in : https://www.linkedin.com/in/v-prasanna-kumar-077089115/
Github : https://github.com/VpkPrasanna
Twitter : https://twitter.com/prasann33774341